
2012年6月21日
独立行政法人 理化学研究所
君は君、我は我なり、他人の価値観を学ぶ脳機能の解明
-人はどうして、多様な価値観を持つ他人に対応できるのか?-
ポイント
fMRI実験により、他人の価値観を理解する脳の仕組みを世界で初めて解明
対人関係障害疾患の解明や社会性を備えたロボットの開発などへの貢献が期待
要旨
理化学研究所脳科学総合研究センターの中原裕之チームリーダー、鈴木真介客員研究員らは、fMRI実験※1で計測された脳活動を意思決定の脳計算モデル※2で解析することで、ヒトの脳が、「他人のココロのシミュレーション※3による学習」と「他人の行動観察による学習」を統合して、他人の価値観を学ぶことを世界で初めて科学的に解明しました。
「相手の気持ちを考える」- たとえば、価値観を共有する恋人、あるいは考え方の違う職場の上司、私たちはいろいろな他人の心や行動を予測します。でも、「私たちは『他人の心』を直接は見れないのに、なぜ予測ができるのか?」、鈴木研究員(当時)の素直な疑問がこの研究の出発点でした。古くからさまざまな議論があり、他人の心のプロセスをあたかも自分のプロセスとして再現する“シミュレーション説”とシミュレーションは不必要で、他人が何にどう反応するかのパターンのみを学習する“行動パターン説※4”がそれぞれ支持を得てきました。しかし、科学的検証が難しく、どちらの説が正しいか、ヒトの脳でどう実現されるか、未だ謎のままでした。
今回の研究では、それぞれの説の脳計算モデルを構築し、被験者が他人の価値判断を予測するfMRI実験を行いました。モデルの挙動と行動データの比較から、実は2つの説を統合した脳計算モデルが最も適切であること、つまり、ヒトはシミュレーション学習に行動パターン学習を加えることで他人の価値観を学習することを突き止めました。さらに、脳活動の分析から、前頭葉※5内で、シミュレーション学習が確かに「自分の価値判断」と同じ領域で、行動パターン学習が別領域で実現されることを発見しました。これは、脳計算モデルとして具体化された、2つの学習の情報処理機能がヒト脳に存在すること、そして、2つの学習が異なる脳領域で処理されることを示しています。「私たちが、多様な価値観をもつ他人に応対できるのはこの2つの脳機能が補完しあうからでしょう」と中原チームリーダーは語っています。
この成果は、将来、対人関係障害などの精神疾患の究明や、多様な価値観を学び対処する社会性をもつコンピューターやロボットの開発への貢献が期待されます。ヒトの社会知性の神経的基盤の解明、そして、諸処の社会科学で扱われる政治・経済・社会の問題にヒト脳機能理解から迫る神経経済学・統合人間脳科学に貢献します。
本研究は、独立行政法人情報通信研究機構・脳情報通信融合研究センターと独立行政法人国立精神・神経医療研究センターの研究者らと共同で、科学研究費補助金(基盤研究B、特定領域研究「統合脳」)の支援を受けました。本成果は、米国の科学雑誌『Neuron』(オンライン版、6月20日付け:日本時間6月21日)に掲載されます。
背景
「相手の気持ちを考えなければ…」。私たちは一生涯で何度この言葉に立ち返ることでしょうか。他人の心を理解して行動することは、私たち人間の社会生活上の根本的な能力です。一方、私たちは「他人の心」を直接見ることはできません。では私たちはどうやって他人の心を理解するのでしょうか?古くからさまざまな議論があり、有力な説の1つは、“シミュレーション説” で「自分の心のプロセスを基にして、他人の心のプロセスをあたかも自分のプロセスとして実現する」ものです。他方、“行動パターン説” もあり 「シミュレーションは不必要で、他人が何にどう反応するかのパターンを学習して、他人の目に見える行動を当てている」も捨てがたいとして支持されてきました。これらの説のどちらが正しいか、そして、私たちヒトの脳で実際にどう実現されているのか、分かっていませんでした。「こころ」が非常に複雑な概念であり、科学的な実験で検証することが難しかったからです。
研究手法と成果
科学実験では、対象を明確に定義することが不可欠です。特に複雑な働きから成り立つ脳の機能を理解には、そのプロセス(脳の情報処理のプロセス)を数理的な計算モデルで記述することで、その機能を定量的に検証することが重要です。今回の研究では、特に、報酬予測という価値判断の意思決定に焦点をあてました。これは、今までのヒトおよび動物の脳研究の蓄積から、報酬量の予測に基づく行動選択(価値判断に基づく意思決定)を繰り返し行うなかで、予測した報酬量と実際の報酬量の違いである「報酬予測誤差」を手掛かりに、ヒトが適切な報酬予測を学習することを根拠にしています。しかも、この報酬予測誤差学習の脳計算モデルが定式化されており、理論と実験を組み合わせる本研究に適しているからです。これをもとにして、「ヒトはどうやって他人の価値判断を学習そして予測するのか」を明らかにするために研究を進めました。
本研究では、さらに、計測したヒト脳活動を、モデル化解析と呼ばれるデータ解析手法で解析しました。ある仮説に基づく脳計算モデルは、その仮説に基づいた実際の行動の予言とともに、仮説から脳の働き(脳の計算、情報処理ともいえる)も予言します。したがって、もし仮説(脳計算モデル)が、適切であれば、行動データによく対応し、さらに挙動に対応する十分な脳活動を示すはずです。モデル化解析では、複数の仮説を、それぞれの脳計算モデルがどれだけ行動データに対応するか調べることで、行動レベルの適切な仮説を選ぶと同時に、その働きに対応する脳活動を調べます。これにより、複雑な脳の働きを、定量的に把握すると同時に、行動と脳情報処理の両方の検証を同時に行います。
本研究では、30名を超える被験者がfMRI装置に入り、2つの実験課題を行いました。1つは、今までの知見を利用した、本人が自分のために報酬予測を行う「報酬学習課題(図1A)」です。「報酬学習課題」では、被験者は「2つの図形のどちらかを選び、その選択が正しければ報酬を得る」という試行を繰り返し行いました(正しい図形は各試行で確率的に決まります)。この課題では、報酬予測誤差学習の脳計算モデルが被験者のココロの中のプロセスに対応します。
そして、もう1つの新たな課題は「他者予測課題(報酬学習課題を遂行中の他人の行動を予測する課題:図1B)」です。このとき、シミュレーション説に基づけば、他人のココロの中の報酬予測誤差学習のプロセスを、「(被験者本人の報酬予測誤差学習のプロセスを利用して)他人のプロセスを自分の脳内で再現する」はずです。この脳計算モデルは、最初の課題で用いた報酬予測誤差学習の脳計算モデルを援用することで実現できます。一方で、行動パターン説の脳計算モデルは新たに構築する必要がありました。私たちは「予測した他人の選択と、実際の他人の選択を比べる行動予測誤差を用いて、他人の価値判断を学習する」という、行動パターン説に対応する脳計算モデルの構築に成功しました。これにより2つの説を、脳計算モデルに基づいて定量的に評価することが可能になりました。
最初に「報酬学習課題」のデータを解析しました。第一に、行動データと報酬予測誤差学習の脳計算モデルの振る舞いを比較することで、確かに、被験者が報酬予測誤差を利用して報酬予測を学習していることを確かめました。次に、脳計算モデルの挙動をもとにして、対応する脳活動データを調べることで、「報酬予測誤差に基づく学習」そして「価値判断に基づく意思決定」の両方が、前頭葉の腹内側部で処理される(図2右の青い領域)ことを確かめました。
その上で「他者予測課題」での行動データを詳細に解析しました。これから、シミュレーション説、そして行動パターン説の個々の脳計算モデルよりも、両方の計算モデルを統合した脳計算モデルの挙動が、行動データと最も対応することを発見しました。この結果は、どちらか一方の説だけでは正しくないことを示しています。むしろ、2つの説を統合させることが正しい、つまり、ヒトは、シミュレーションによる学習と相手の行動パターンによる学習を統合して用いることで、他者の価値判断を学んでいることを示しています。
さらに、脳活動データをモデル化解析手法で調べることで、2つの学習に対応する脳活動、すなわち、2つの学習それぞれの具体的な情報処理が脳に存在することを見出しました。さらに、その脳活動は、社会性などに関連すると考えられている前頭葉の内側部(図2左)の別々の領域で行われていることを発見しました(図2右)。シミュレーション学習の脳領域(図2右の赤い領域)が、確かに「報酬学習課題」で被験者が自分自身のために行っていた報酬予測の学習と価値判断の選択のための脳領域(図2右の青い領域)と重なることを発見しました(図2右の紫の領域)。これは、自分のプロセスを基に他人のプロセスをシミュレーションしていることを脳活動として実証しています。行動パターン学習は別領域(図2右の緑の領域)で処理されていました。ヒトの脳は、シミュレーションを通じて他人の価値観を学習するだけでなく、他人の行動観察に応じて起きる前頭葉の別領域の活動により、その学習をたえず補正することで、他人の価値観をより精緻に学習していることが分かりました。
そもそも私たちヒトは多様な価値観をもっています。本研究で明らかにされた、シミュレーション学習と行動パターン学習を統合するヒト脳の他人の価値判断の学習は、他人の多様な価値観への対処に役立つと思われます。自分と似た価値観をもつ他人について学ぶにはシミュレーション学習が主な役割を担うと思われます。一方で、自分と異なる価値観をもつ他人には、シミュレーション学習だけでは対処しきれない可能性が高く、行動パターン学習との統合学習が特に効力をもつと考えられます。
本成果は、独立行政法人理化学研究所 脳科学総合研究センター 理論統合脳科学研究チーム(中原裕之チームリーダー)の鈴木真介・原澤寛浩が、機能的磁気共鳴画像測定支援ユニット(程康・上野賢一)の協力のもと、Justin Gardner (Gardner研究ユニット)と、そして春野雅彦主任研究員(独立行政法人情報通信研究機構・脳情報通信融合研究センター)・一戸紀孝部長(独立行政法人国立精神・神経医療研究センター 神経研究所微細構造研究部)と共同で進めた研究による成果です。
今後の期待
脳科学は現在急速に発展しています。特に、近年「ヒトの高度な社会知性を支える脳の仕組み」の解明へと広がりを見せています。研究チームは今回、社会知性の根幹にある「他人の心を理解する能力」について、脳の仕組みの一端を明らかにしました。この成果は、ヒトの社会知性の神経的基盤の解明に貢献し、将来、対人関係に支障がある精神疾患の究明、多様な価値観を学び対処する社会性をもつコンピューターやロボットの開発への貢献が期待されます。また、本研究のアプローチ、脳計算モデルあるいはモデル化解析手法を用いた社会知性の脳機能理解の研究は、今後、大きな展開が期待されており、諸処の社会科学で扱われる政治・経済・社会の問題にヒト脳機能理解から迫る神経経済学や社会脳科学、ひいては統合人間脳科学に貢献します。
原論文情報
Shinsuke Suzuki, Norihiro Harasawa, Kenichi Ueno, Justin L Gardner, Noritaka Ichinohe, Masahiko Haruno, Kang Cheng, Hiroyuki Nakahara. “Learning to simulate others’ decisions”. Neuron, 2012, doi: 10.1016/j.neuron.2012.04.030
発表者
独立行政法人理化学研究所
脳科学総合研究センター 心と知性への挑戦コア 理論統合脳科学研究チーム
チームリーダー 中原 裕之(なかはら ひろゆき)
Tel: 048-467-9663 / Fax: 048-467-9643
お問い合わせ先
脳科学研究推進部 企画課
Tel: 048-467-9757 / Fax: 048-462-4914
補足説明
fMRI実験
ヒトの脳活動に関連した血流動態反応を視覚化する方法の1つである機能的核磁気共鳴画像法(fMRI)を利用して、心理実験課題を遂行中のヒト脳活動を計測する実験のこと。課題遂行に関連する脳活動が分かる。さらに、今回の研究のように、その脳活動をモデル化解析手法を適用して解析することで、その課題遂行のための脳情報処理(脳計算モデル、その仮説に基づく脳内の情報処理のプロセス)に対応する脳活動を検証することができる。
脳計算モデル
脳の働きを数学的に定式化して表したもの。ここでは,報酬予測誤差を利用した報酬予測の学習と、その学習に基づいた価値判断の意思決定の脳の働きを記述した数理モデルを意味する。
シミュレーション
ある現象をコンピューター上などに模擬的に再現すること。ここでは、他人の価値判断のプロセスを、自分の価値判断のプロセスを礎にして、自分の心の中で再現することを意味する。シミュレーション・セオリー (Simulation theory)と呼ばれている。
行動パターン説
シミュレーション・セオリー(Simulation theory)と対比される説として、シミュレーションなしで他者の行動パターンの知識あるいは理論を作り上げるという意味で、この「行動パターン説」はセオリー・セオリー(Theory theory)と呼ばれている。
前頭葉
脳(大脳皮質)の前部の領域(図2参照)。一般に行動計画、問題解決に関連すると考えられている領域で、社会性や複雑な価値判断にも関連するとされている。
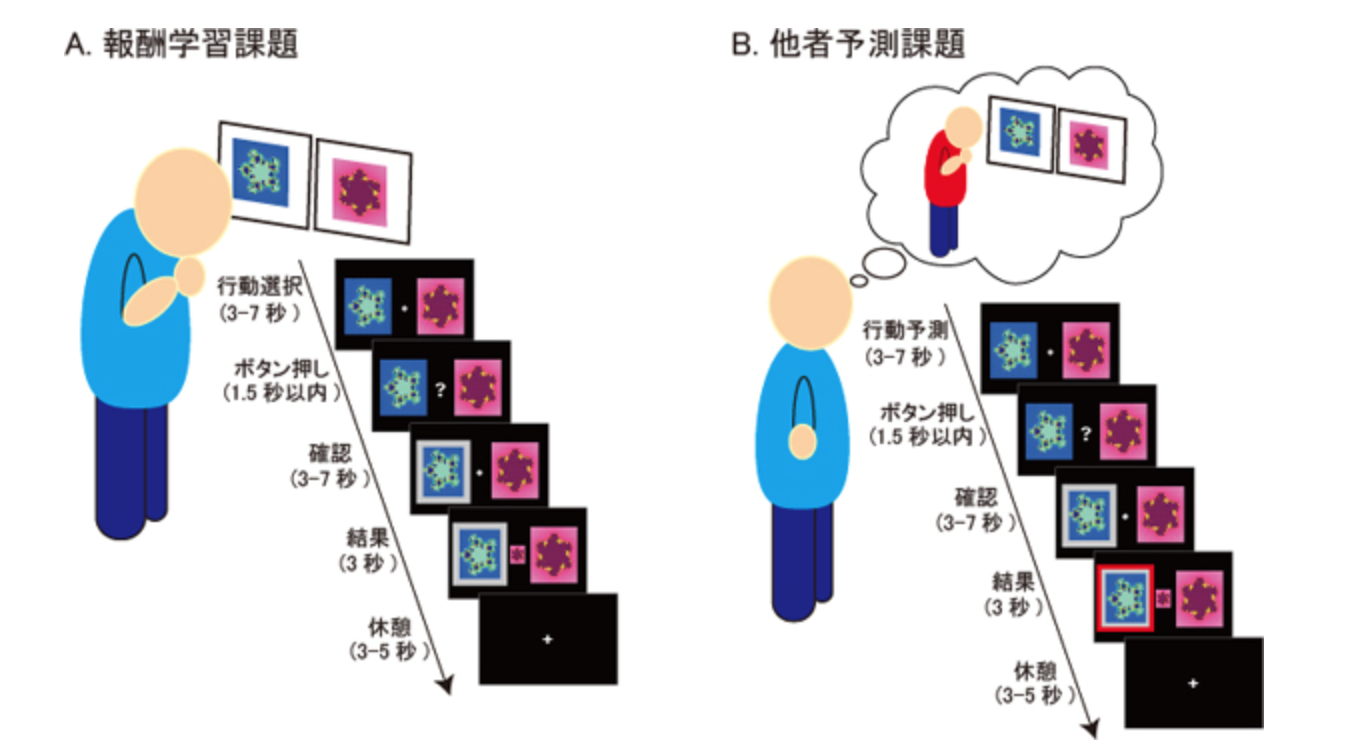
図1 実験課題:報酬学習課題(A)と他者予測課題(B)
(A)報酬学習課題: 被験者は「2つの図形のどちらかを選び、その後、選んだ図形が「正解」であれば報酬を得る」という試行を繰り返し行う。上の図で、被験者が選択した図形は「確認」のときに「灰色枠」で示され、その被験者の選んだ図形が、「結果」のときに中央に出る図形と一致していれば、被験者は報酬を得ることになる。高報酬を得るためには、被験者は試行を重ねて行く中でどちらの図形が正解になる確率が高いのか(価値判断)を学習していく必要がある。
(B)他者予測課題: 被験者は「報酬学習課題を遂行中の他人の行動」を予測。予測が的中すれば報酬がもらえる。(「結果」で、他者の選択は「赤枠」で示される。被験者の選択(「灰色枠」)がこの「赤枠」と一致しているときに、被験者は報酬をもらえる。注記)この図の課題は、簡単に理解できるように、オリジナルの実験課題を簡略化して示している。
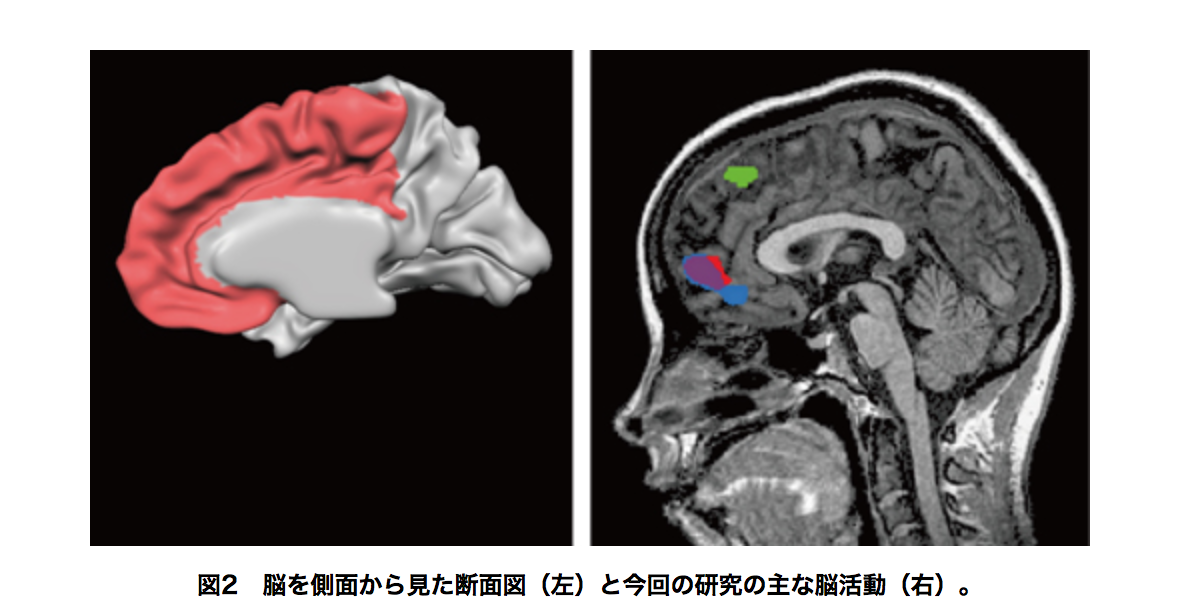
左:脳の中央部を側面から見た図(左側が顔の側に対応し、右側が頭の後ろ側に対応)。オレンジの領域が前頭葉。
右:報酬学習課題を遂行中の脳活動(青)と他者予測課題を遂行中の脳活動(赤、緑)。青:自分自身の報酬予測誤差学習と価値判断による行動選択に関連する脳活動。赤:他者の報酬予測誤差学習をシミュレーションするのに関連する脳活動(シミュレーションした、他者の「報酬予測誤差」を処理する脳活動)。緑:他者の行動パターン学習に関連する脳活動(他者の「行動予測誤差」を処理する脳活動)。(左図は、BrainTutor (free software)の図から掲載。)



